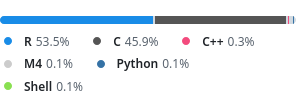
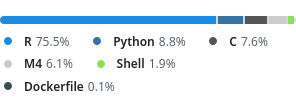
provide a high number of test cases “for free” to new implementations
Mitigations: continuous benchmarking
Request for help
Low diversity of test datasets.
Artür discovered a lot of edge cases and missing features when implementing Zarr support in anndataR.
Vendoring vs Native implementation
Cons vendoring (1/3):
Clash with CRAN / Bioconductor policies
* checking compiled code ... WARNING
Note: information on .o files is not available
File ‘/home/biocbuild/bbs-3.22-bioc/R/site-library/rhdf5/libs/rhdf5.so’:
Found ‘__sprintf_chk’, possibly from ‘sprintf’ (C)
Found ‘abort’, possibly from ‘abort’ (C)
Found ‘rand_r’, possibly from ‘rand_r’ (C)
Found ‘stderr’, possibly from ‘stderr’ (C)
Found ‘stdout’, possibly from ‘stdout’ (C)
Compiled code should not call entry points which might terminate R nor
write to stdout/stderr instead of to the console, nor use Fortran I/O
nor system RNGs nor [v]sprintf. The detected symbols are linked into
the code but might come from libraries and not actually be called.
Vendoring vs Native implementation
Cons vendoring (2/3):
Larger library (size & API) than needed
is manually sorting through the files worth it?
Patching process:
git patch vs script
applied to vendored version vs applied at build time
Underlying library influence wrapper API = less idiomatic API
Vendoring vs Native implementation
Cons vendoring (3/3):
Clash with Debian policy
Lower control on update timing
Support for older versions: challenges
By vendoring, we can make sure all users have the same version.
vs wrapping a system library:
Support for older versions: policy
We always support reading from older formats
Support for writing to older formats is done on a best effort basis
Making updates easier
Convince libraries to stick more closely to semantic versioning