xlcutter 0.1.0
Hugo Gruson 
The starting point of every analysis is getting good data. Importantly, this data should be accessible, and not be locked in, e.g., a PDF. Many data analysts and data scientists will also tell you that this data should be rectangular, or even better tidy data. Indeed, our most powerful tools for data analysis work on data.frame on any kind of similar rectangular format.
But for various reasons, ranging from legacy data to convenience, data producers don’t always follow this recommendation. Sometimes, excel spreadsheets will be used as forms rather than actual tables. In this context, you cannot reason in terms of rows and columns but you have to think at the level of the individual cell.
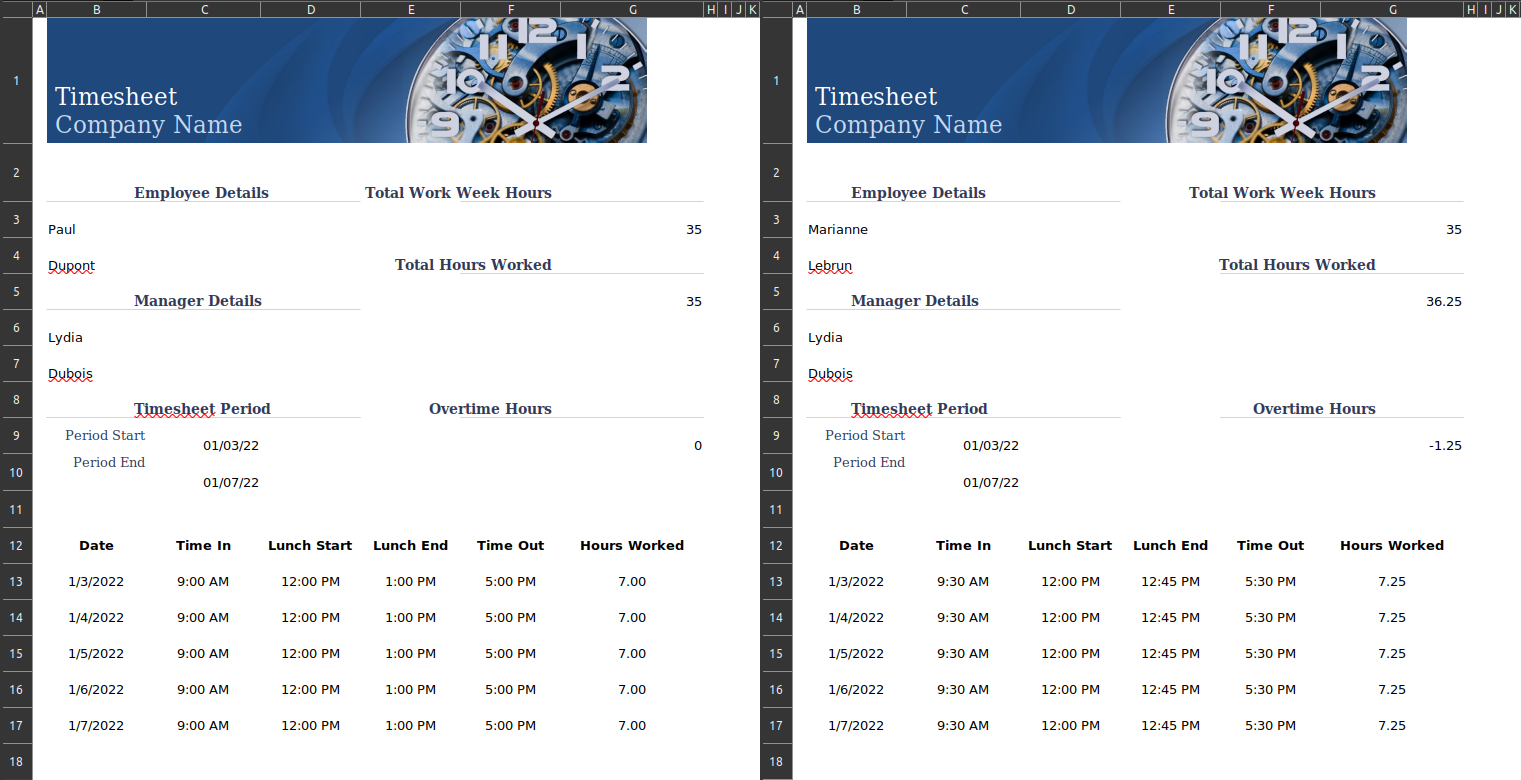
And even though we have good tools for “quasi-rectangular” data, this kind of cell-based format is very difficult to turn into an easy to analyse, rectangular data. If you have just one single short file, you may be tempted to copy/paste the values and solve this issue manually. But this approach cannot work if you have many non-rectangular files. You need to find a way to programmatically achieve this.
I recently inherited a script that was dealing with this issue of a large number of non-rectangular xlsx files based on the same template. Their approach was to import the file into R with readxl, as if the file was rectangular, and then to extract individual cells via their row and column index.
f <- list.files("excel")
m <- lapply(f, readxl::read_xlsx, simplify = FALSE)
firstnames <- sapply(m, "[[", 3, 2)
lastnames <- sapply(m, "[[", 4, 2)
df <- list2DF(list(firstnames, lastnames))This achieved the intended goal but:
- It is not very robust because readxl is designed to work with rectangular, or quasi-rectangular files. It might manage to import non-rectangular files but it might also create problems because there is an expectation of some amount of consistency within a given column.
- It results in a very long, and difficult to understand script. As a consequence, it is difficult to update each time the template changes. In particular, I struggled with the indexing because columns in excel are not indexed as number but as letters and I could never remember if the header was included or not (which would shift the row indexing by one).
There is however one very powerful tool to work with cell-based spreadsheets: tidyxl. It imports cell-based data without trying to coerce it as a rectangular data.frame. So it provides an interesting base for what we are trying to achieve but it doesn’t go all the way because we want to get rectangular data at the end.
This is where the idea for a new package came into fruition: xlcutter. An important design detail is that I wanted to be able to visualize how my data would be converted into rectangular data, which precise cell in each file would be collated to generate the new columns.
Since we are already working with a list of excel files based on the same format, the most natural way that appeared was to use one similarly formatted excel file as a template with a special syntax to detect cells that will be extracted (by default { column_name }). The visualization design constraint is immediately addressed since you can open the template as any excel file and immediately see the special cells 1.
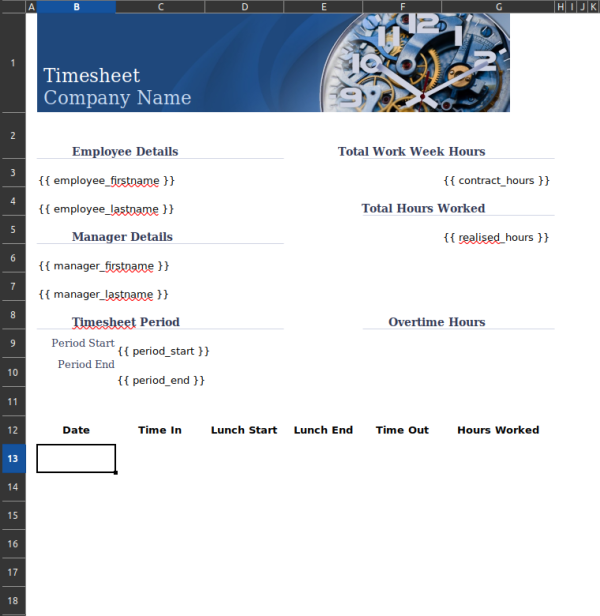
The xlcutter package provides one major function: xlsx_cutter(). It takes two crucial arguments: a list of excel files to parse and consolidate into a unique rectangular dataset and a template defining the specific cells to extract and the name of the column where they will end up. Sensible defaults are provided for the other arguments and you’re less likely to need to change them.
f <- list.files("excel")
template <- "template.xlsx"
xlcutter::xlsx_cutter(f, template)As you can see in the example above, the package also takes care of the loop for you so you can parse an entire folder of excel files based on the same template in a single line!
Conclusion
I am very excited to release this package on CRAN because I believe it provides a convenient solution for parsing non-rectangular data files. Its main strength is the fact that templates can be edited by non-programmers since they are provided as excel files. I’m looking forward to hearing how the community uses it and welcome any feedback and contributions!
Footnotes
since only the cell content is taken into account but not the cell formatting, you can even make the special cells pop out even more by adding some colour to them↩︎